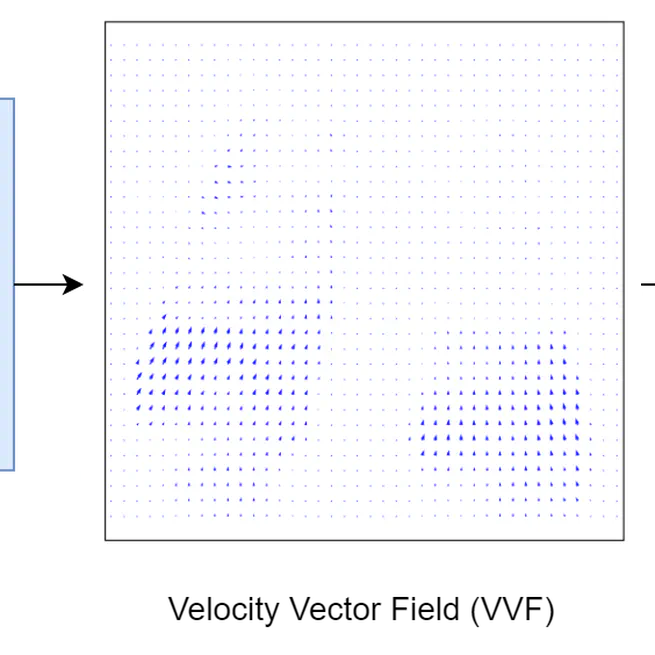
Continuous sPatial-Temporal Deformable Image Registration (CPT-DIR) for motion modelling in radiotherapy: beyond classic voxel-based methods
By leveraging the continuous representations, the CPT-DIR method enhances registration and interpolation accuracy, automation, and speed.
Dec 26, 2025
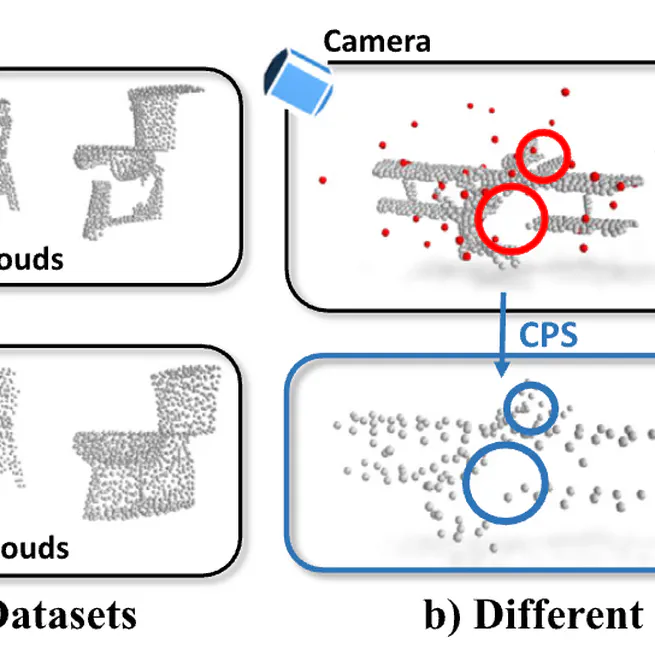
ModelNet-O: A large-scale synthetic dataset for occlusion-aware point cloud classification
A large-scale synthetic dataset ModelNet-O for occlusion-aware point cloud classification, featuring diverse occlusion patterns and complex object arrangements to evaluate model robustness under occlusion conditions.
Jun 19, 2024
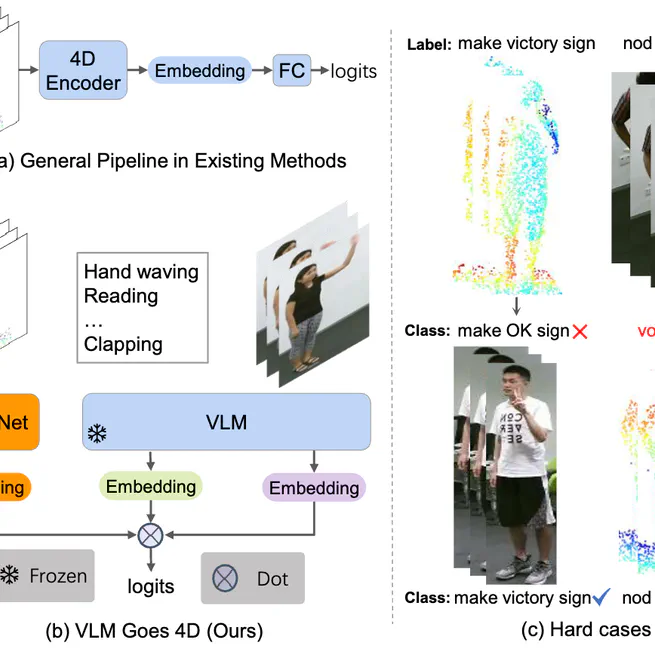
VG4D: Vision-Language Model Goes 4D Video Recognition
A Vision-Language Model Goes 4D (VG4D) framework that transfers VLM knowledge to 4D point cloud networks for improved video recognition, achieving state-of-the-art performance on action recognition datasets.
May 13, 2024
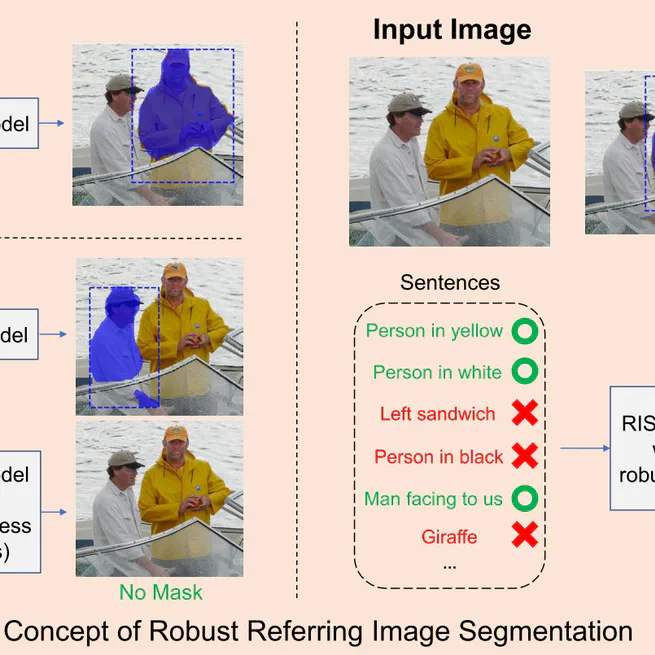
Towards robust referring image segmentation
We propose a novel ranking loss function, named Bi-directional Exponential Angular Triplet Loss, to help learn an angularly separable common feature space by explicitly constraining the included angles between embedding vectors.
Mar 5, 2024
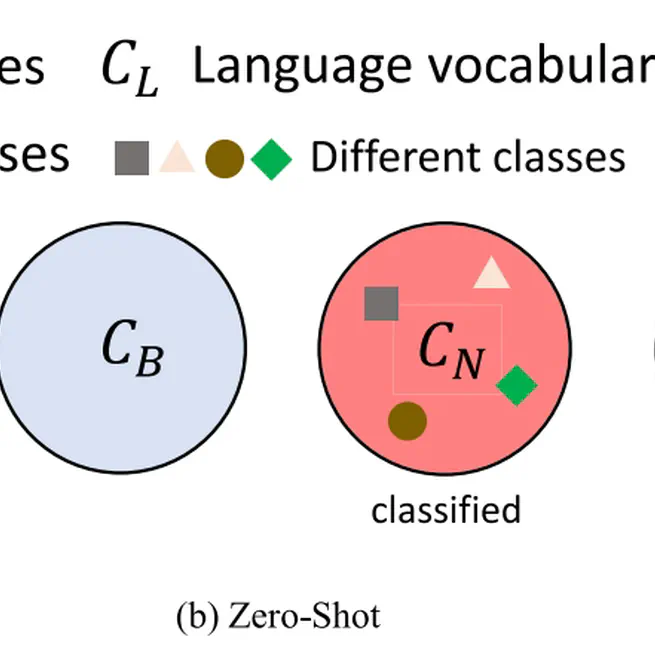
Towards open vocabulary learning: A survey
This survey offers a detailed examination of the latest developments in open vocabulary learning in computer vision, which appears to be a first of its kind. We provide an overview of the necessary background knowledge, which includes fundamental concepts and introductory knowledge of detection, segmentation, and vision language pre-training. Following that, we summarize more than 50 different models used for various scene understanding tasks. For each task, we categorize the methods based on their technical viewpoint. Additionally, we provide information regarding several closely related domains. In the experiment section, we provide a detailed description of the settings and compare results fairly. Finally, we summarize several challenges and also point out several future research directions for open vocabulary learning.
Feb 5, 2024
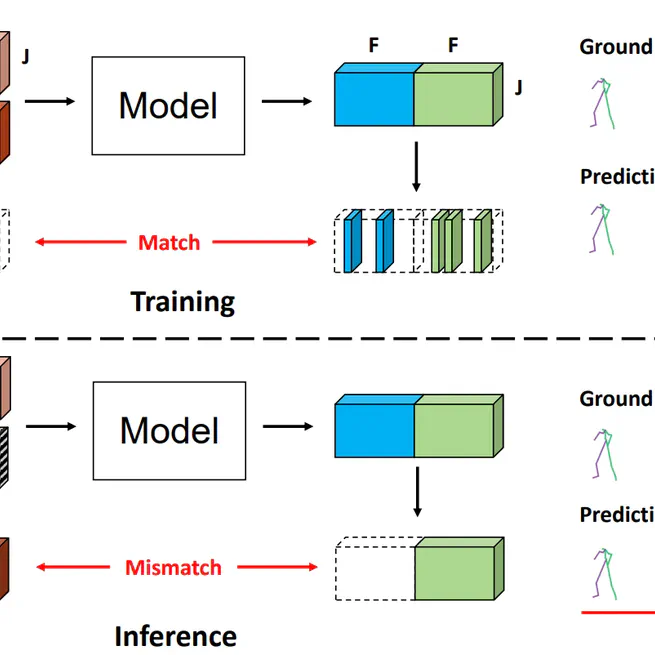
Skeleton-in-context: Unified skeleton sequence modeling with in-context learning
In this work, we propose the Skeleton-in-Context, designed to process multiple skeleton-base tasks simultaneously after just one training time. Specifically, we build a novel skeleton-based in-context benchmark covering various tasks. In particular, we propose skeleton prompts composed of TGP and TUP, which solve the overfitting problem of skeleton sequence data trained under the training framework commonly applied in previous 2D and 3D in-context models. Besides, we demonstrate that our model can generalize to different datasets and new tasks, such as motion completion. We hope our research builds the first step in the exploration of in-context learning for skeleton-based sequences, which paves the way for further research in this area.
Dec 15, 2023
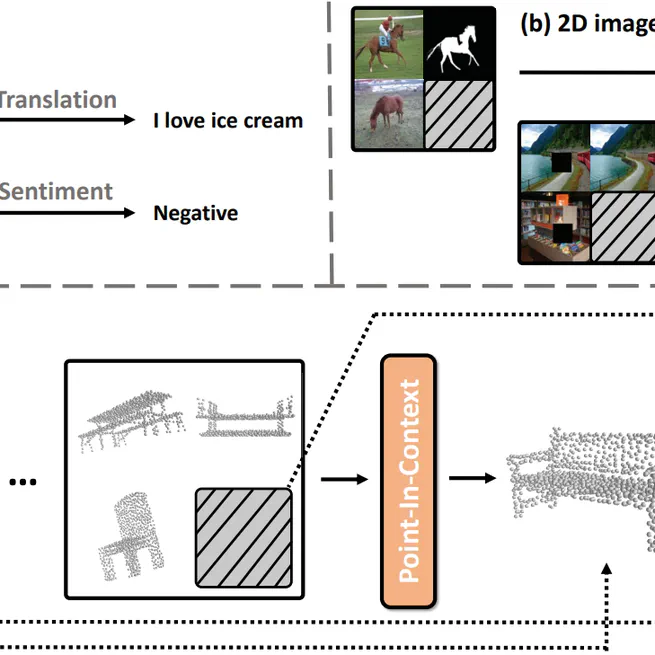
Explore In-Context Learning for 3D Point Cloud Understanding
We propose Point-In-Context (PIC), the first framework adopting the in-context learning paradigm for 3D point cloud understanding. Specifically, we set up an extensive dataset of point cloud pairs with four fundamental tasks to achieve in-context ability. We propose effective designs that facilitate the training and solve the inherited information leakage problem. PIC shows its excellent learning capacity, achieves comparable results with single-task models, and outperforms multitask models on all four tasks. Besides, it shows good generalization ability to out-of-distribution samples and unseen tasks and has great potential via selecting higher-quality prompts. We hope it paves the way for further exploration of in-context learning in the 3D modalities.
Dec 10, 2023
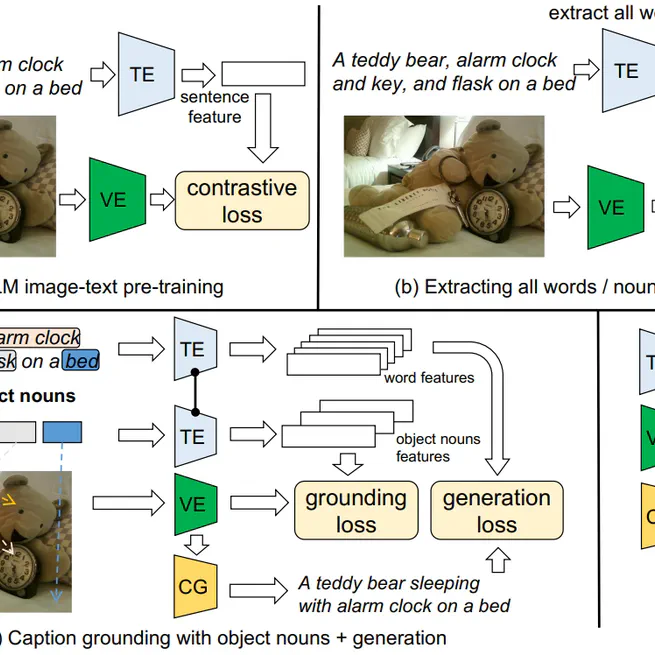
Betrayed by captions: Joint caption grounding and generation for open vocabulary instance segmentation
This paper presents a joint Caption Grounding and Generation (CGG) framework for instance-level open vocabulary segmentation. The main contributions are: (1) using fine-grained object nouns in captions to improve grounding with object queries. (2) using captions as supervision signals to extract rich information from other words helps identify novel categories. To our knowledge, this paper is the first to unify segmentation and caption generation for open vocabulary learning. The proposed framework significantly improves OVIS and OSPS and comparable results on OVOD without pre-training on large-scale datasets.
Oct 2, 2023
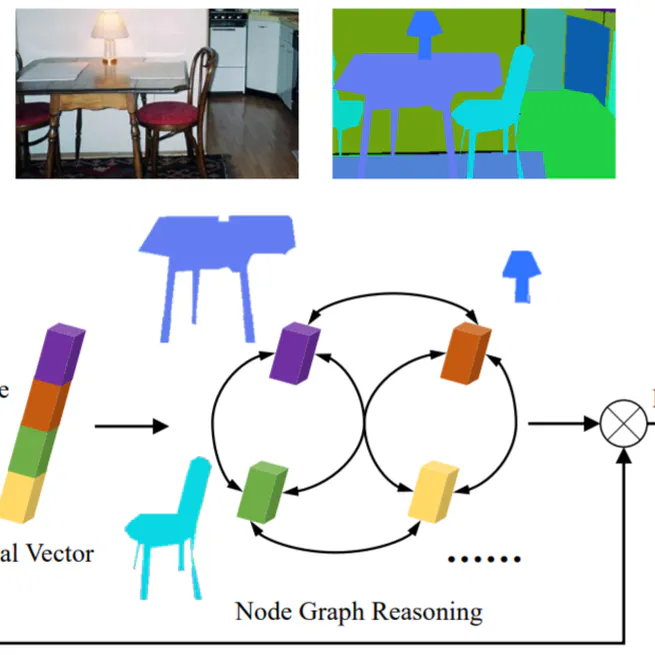
Towards efficient scene understanding via squeeze reasoning
Jul 30, 2021
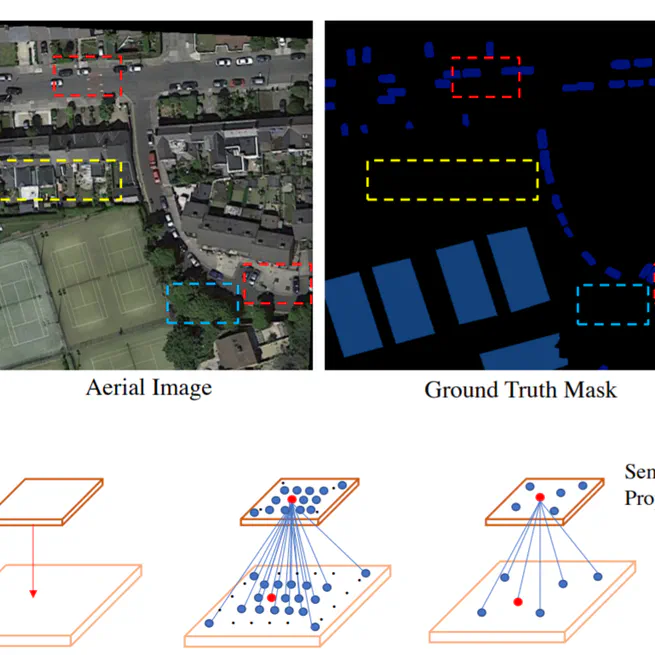
PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation
Feb 13, 2021
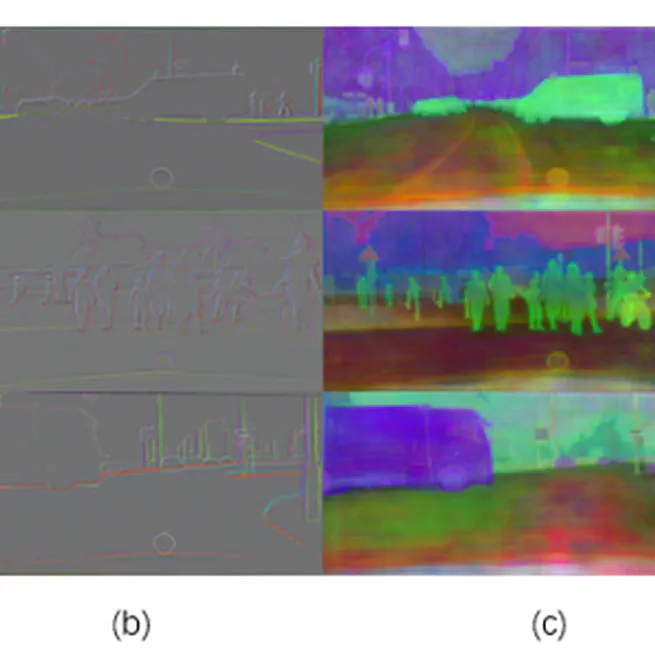
Improving Semantic Segmentation via Decoupled Body and Edge Supervision
Jul 3, 2020