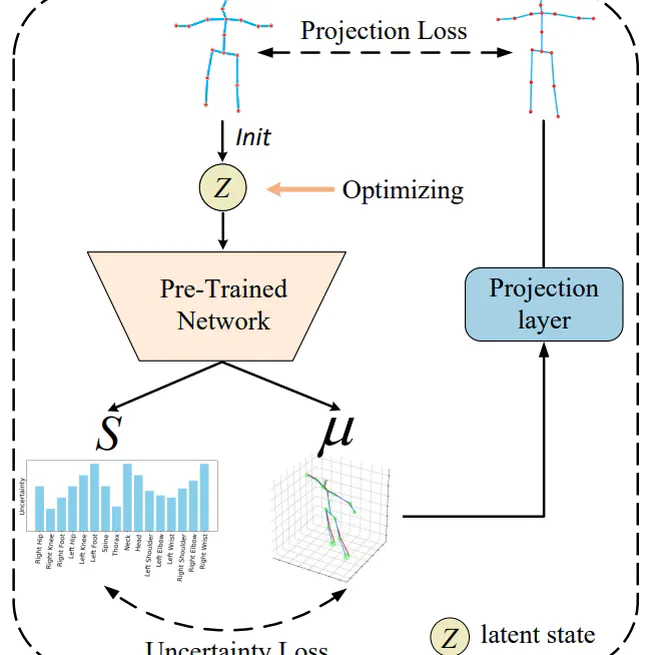
Uncertainty-Aware Testing-Time Optimization for 3D Human Pose Estimation
In this paper, we propose an Uncertainty-Aware testing-time Optimization (UAO) framework for 3D human pose estimation. During the training process, we propose the GUMLP to estimate 3D results and uncertainty values for each joint. For test-time optimization, our UAO framework freezes the pre-trained network parameters and optimizes a latent state initialized by the input 2D pose. To constrain the optimization direction in both 2D and 3D spaces, projection and uncertainty constraints are applied. Extensive experiments show that our approach achieves state-of-the-art performance on two popular datasets
Jun 15, 2025
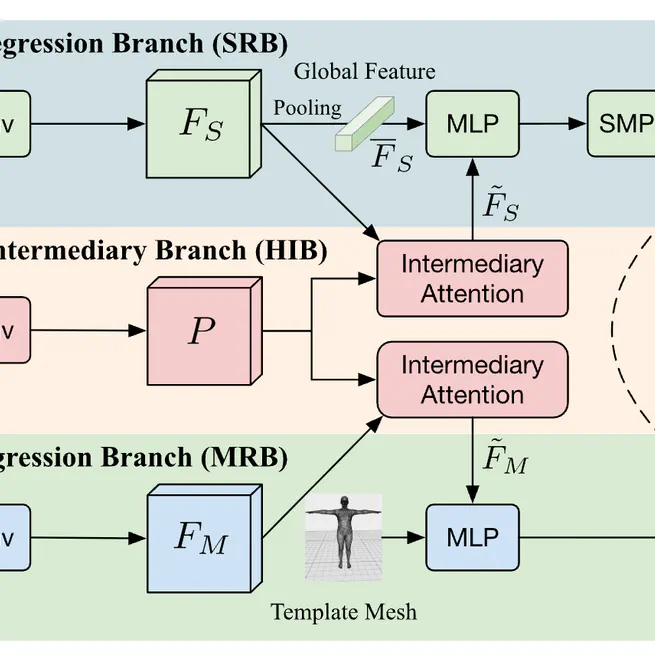
HYRE: Hybrid Regressor for 3D Human Pose and Shape Estimation
A novel Hybrid Regressor (HYRE) that combines parametric and non-parametric paradigms for 3D human pose and shape estimation, bridging the gap between physically plausible and pixel-aligned results through joint learning.
Dec 25, 2024
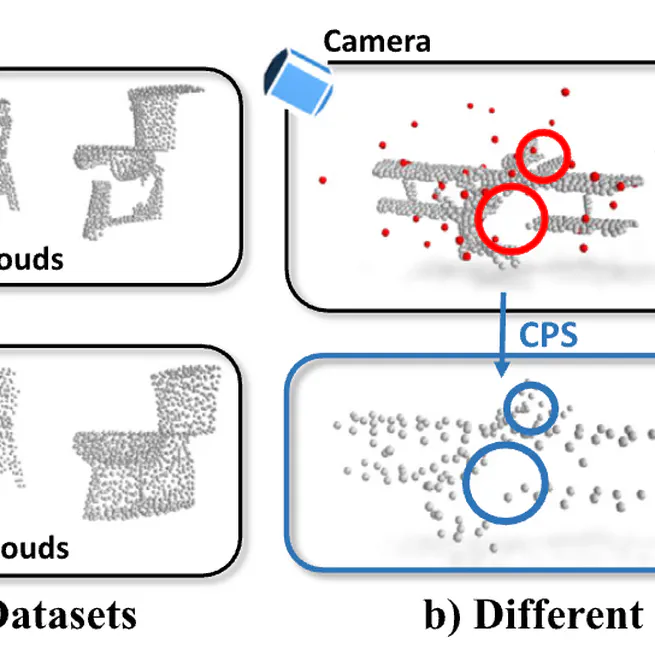
ModelNet-O: A large-scale synthetic dataset for occlusion-aware point cloud classification
A large-scale synthetic dataset ModelNet-O for occlusion-aware point cloud classification, featuring diverse occlusion patterns and complex object arrangements to evaluate model robustness under occlusion conditions.
Jun 19, 2024
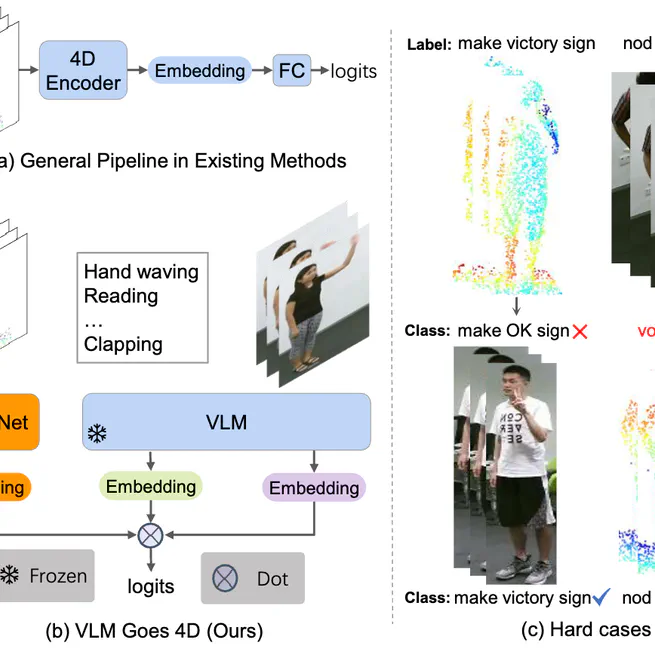
VG4D: Vision-Language Model Goes 4D Video Recognition
A Vision-Language Model Goes 4D (VG4D) framework that transfers VLM knowledge to 4D point cloud networks for improved video recognition, achieving state-of-the-art performance on action recognition datasets.
May 13, 2024
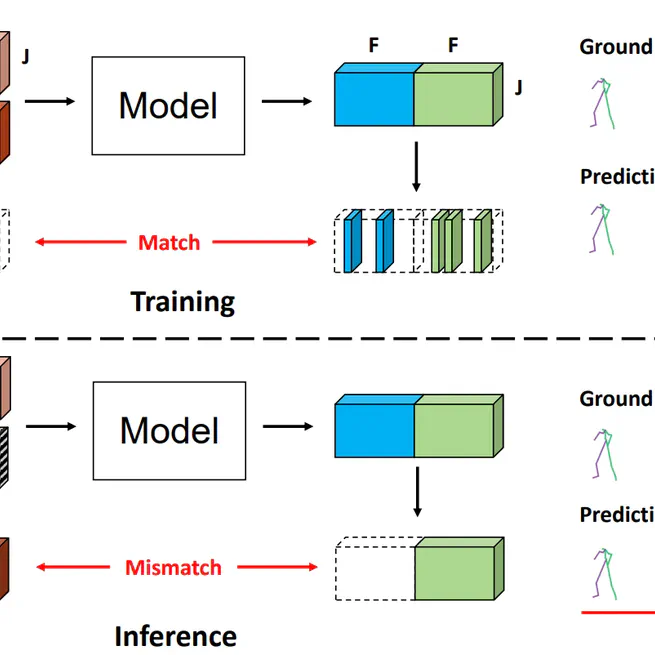
Skeleton-in-context: Unified skeleton sequence modeling with in-context learning
In this work, we propose the Skeleton-in-Context, designed to process multiple skeleton-base tasks simultaneously after just one training time. Specifically, we build a novel skeleton-based in-context benchmark covering various tasks. In particular, we propose skeleton prompts composed of TGP and TUP, which solve the overfitting problem of skeleton sequence data trained under the training framework commonly applied in previous 2D and 3D in-context models. Besides, we demonstrate that our model can generalize to different datasets and new tasks, such as motion completion. We hope our research builds the first step in the exploration of in-context learning for skeleton-based sequences, which paves the way for further research in this area.
Dec 15, 2023
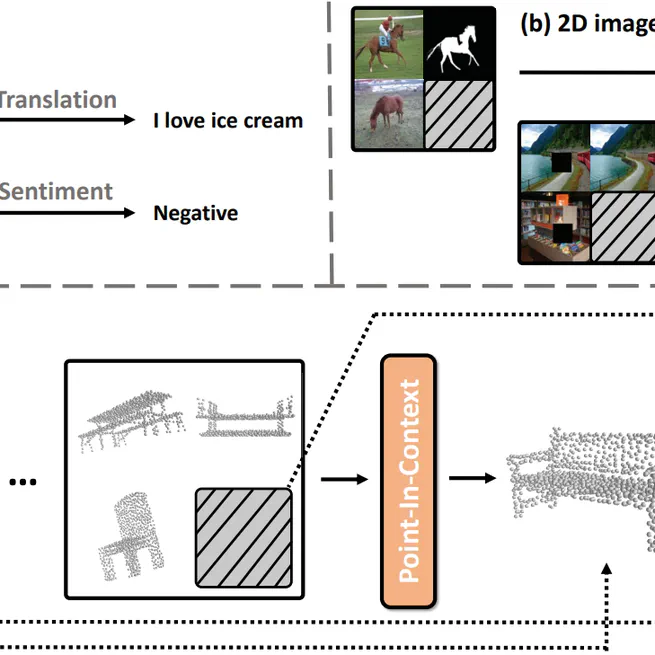
Explore In-Context Learning for 3D Point Cloud Understanding
We propose Point-In-Context (PIC), the first framework adopting the in-context learning paradigm for 3D point cloud understanding. Specifically, we set up an extensive dataset of point cloud pairs with four fundamental tasks to achieve in-context ability. We propose effective designs that facilitate the training and solve the inherited information leakage problem. PIC shows its excellent learning capacity, achieves comparable results with single-task models, and outperforms multitask models on all four tasks. Besides, it shows good generalization ability to out-of-distribution samples and unseen tasks and has great potential via selecting higher-quality prompts. We hope it paves the way for further exploration of in-context learning in the 3D modalities.
Dec 10, 2023
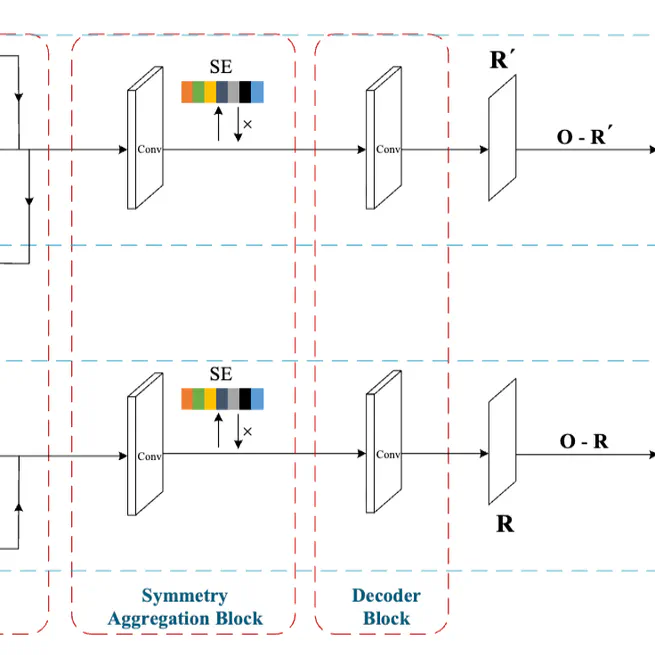
Self-Refining Deep Symmetry Enhanced Network for Rain Removal
A Self-Refining Deep Symmetry Enhanced Network (DSEN) for rain removal that extracts rotation equivariant features and uses a self-refining mechanism to remove accumulated rain streaks in a coarse-to-fine manner.
Sep 22, 2019