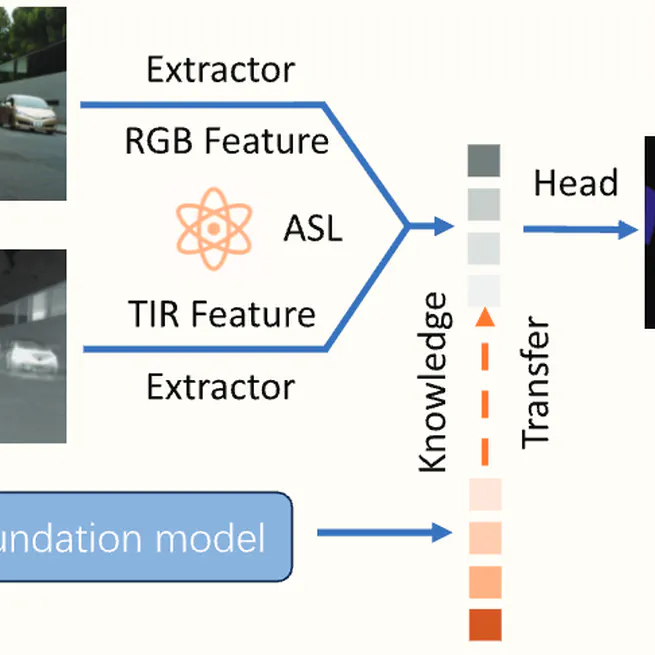
MiLNet: Multiplex Interactive Learning Network for RGB-T Semantic Segmentation
A novel module-free Multiplex Interactive Learning Network (MiLNet) for RGB-T semantic segmentation that integrates multi-model, multi-modal, and multi-level feature learning through asymmetric simulated learning and inverse hierarchical fusion strategies.
Mar 3, 2025
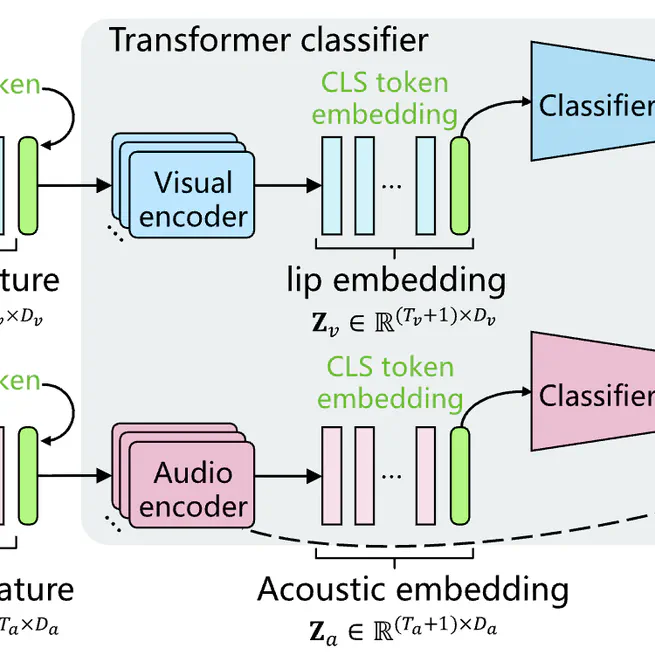
Audio–visual keyword transformer for unconstrained sentence‐level keyword spotting
An Audio–Visual Keyword Transformer (AVKT) network for keyword spotting in unconstrained video clips, using transformer classifier with learnable CLS tokens and decision fusion to achieve high accuracy in both clean and noisy conditions.
Feb 1, 2024